एक प्रक्रिया या कार्य में इसके भीतर दूसरी प्रक्रिया के लिए कॉल हो सकती है। समेत, सबरूटीन खुद को कॉल कर सकता है। इस मामले में, कंप्यूटर परवाह नहीं करता। साथ ही, हमेशा की तरह, वह उन आदेशों को लगातार निष्पादित करता है जो उसे ऊपर से नीचे तक मिलते हैं।
अगर आपको गणित याद है, तो आप गणितीय आगमन के सिद्धांत से मिल सकते हैं। यह इस प्रकार है:
प्रत्येक प्राकृतिक n if के लिए कुछ कथन सत्य है
1. यह n = 1 और के लिए मान्य है
2. किसी भी स्वाभाविक प्राकृतिक n = k के लिए कथन की वैधता से यह अनुसरण करता है कि यह n = k+1. के लिए सत्य है
प्रोग्रामिंग में, इस तकनीक को रिकर्सन
कहा जाता है
रिकर्सन दिए गए सरल आधार मामलों के आधार पर सेट के संदर्भ में वस्तुओं के एक सेट को परिभाषित करने का एक तरीका है।
रिकर्सिव को प्रक्रिया (फ़ंक्शन) भी कहा जाएगा जो स्वयं को सीधे या अन्य प्रक्रियाओं और कार्यों के माध्यम से कॉल करता है
एक पुनरावर्ती प्रक्रिया का एक उदाहरण:
<पूर्व>
<कोड> शून्य आरईसी (इंट ए)
{
अगर (ए एंड जीटी; 0) आरईसी (ए -1);
cout << ए;
}
योजनाबद्ध रूप से, पुनरावर्तन के कार्य को फ़्लोचार्ट द्वारा दर्शाया जा सकता है
Rec() प्रक्रिया को पैरामीटर 3 के साथ निष्पादित किया जाता है। फिर, पैरामीटर 3 के साथ प्रक्रिया के अंदर, पैरामीटर 2 के साथ प्रक्रिया को कॉल किया जाता है, और इसी तरह, जब तक पैरामीटर 0 के साथ प्रक्रिया को कॉल नहीं किया जाता है। जब प्रक्रिया के साथ पैरामीटर 0 कहा जाता है, पुनरावर्ती कॉल पहले से नहीं होगा और पैरामीटर 0 वाली प्रक्रिया संख्या 0 को प्रिंट करेगी और समाप्त हो जाएगी। फिर नियंत्रण को पैरामीटर 1 के साथ प्रक्रिया में वापस स्थानांतरित कर दिया जाता है, यह नंबर 1 को प्रिंट करके अपना काम भी पूरा करता है, और इसी तरह। पैरामीटर 3 के साथ प्रक्रिया से पहले।
जब तक वे अपना काम पूरा नहीं कर लेते, तब तक सभी प्रक्रियाओं को स्मृति में संग्रहीत किया जाता है। समवर्ती प्रक्रियाओं की संख्या को पुनरावर्तन गहराई कहा जाता है।
|
रिकर्सन। लूप सिमुलेशन
हमने देखा है कि पुनरावर्तन एक उपनेमका में निहित निर्देशों का बार-बार निष्पादन है। और यह बदले में चक्र के कार्य के समान है। ऐसी प्रोग्रामिंग भाषाएं हैं जिनमें लूप निर्माण बिल्कुल अनुपस्थित है, उदाहरण के लिए, प्रोलॉग।
for. लूप के काम को सिम्युलेट करने की कोशिश करते हैं
for लूप में एक स्टेप काउंटर वेरिएबल होता है। एक पुनरावर्ती उपनेमका में, ऐसे चर को एक पैरामीटर के रूप में पारित किया जा सकता है।
// प्रक्रिया लूपइमिटेशन () दो मापदंडों के साथ।
// पहला पैरामीटर - स्टेप काउंटर, दूसरा पैरामीटर - चरणों की कुल संख्या।
शून्य लूपइमिटेशन (इंट आई, इंट एन)
{
cout << "हैलो एन" << मैं << एंडल; // ऑपरेटर i के किसी भी मूल्य के लिए दोहराया जाना है
if (i < n) // जब तक लूप काउंटर n के बराबर न हो जाए,
{// पैरामीटर i+1 के साथ प्रक्रिया का एक नया उदाहरण कॉल करें (अगले मान i पर जाएं)।
लूपइमिटेशन (i + 1, n);
}
}
|
रिकर्सन और पुनरावृत्ति
रिकर्सन को समझने के लिए, आपको रिकर्सन को समझने की जरूरत है...
पुनरावृति प्रोग्रामिंग में - एक चरणचक्रीय डेटा संसाधन प्रक्रिया का।
वर्तमान चरण (पुनरावृत्ति) पर अक्सर पुनरावृत्त एल्गोरिदम पिछले चरणों में गणना किए गए समान ऑपरेशन या क्रिया के परिणाम का उपयोग करते हैं। ऐसी गणनाओं का एक उदाहरण पुनरावृत्ति संबंधों की गणना है।
पुनरावर्ती मान का एक सरल उदाहरण भाज्य है: \(N!=1 \cdot 2 \cdot 3 \cdot \ ... \ \cdot N\)।
प्रत्येक चरण (पुनरावृत्ति) पर मूल्य की गणना \(N=N \cdot i\) है। \(N\) के मान की गणना करते समय, हम पहले से संग्रहीत मान लेते हैं \(N\)।< बीआर />
किसी संख्या के क्रमगुणन को पुनरावर्ती सूत्र: का उपयोग करके भी वर्णित किया जा सकता है
\(\begin{equation*} n!= \begin{cases} 1 &\text{n <= 1,}\\ (n-1)! \cdot n &\text{n > 1.} \end{cases} \end{equation*}\)
आप देख सकते हैं कि यह विवरण एक पुनरावर्ती क्रिया से अधिक कुछ नहीं है।
यहां पहली लाइन ( \(n <= 1\)) बेस केस (रिकर्सन टर्मिनेशन कंडीशन) है और दूसरी लाइन अगले स्टेप के लिए ट्रांजिशन है। < br />
<टेबल क्लास = "टेबल-एसएम टेबल-बॉर्डर टेबल-स्ट्राइप्ड टेबल-लिस्ट-टेस्ट">
<शरीर>
| रिकर्सिव फैक्टोरियल फंक्शन |
पुनरावृत्ति एल्गोरिद्म |
<टीडी>
इंट फैक्टोरियल (इंट एन)
{
अगर (एन एंड जीटी; 1)
रिटर्न एन * फैक्टोरियल (एन - 1);
और वापसी 1;
}
<टीडी>
एक्स = 1;
के लिए (i = 2; i <= n; i++)
एक्स = एक्स * मैं;
cout << एक्स;
यह समझा जाना चाहिए कि फ़ंक्शन कॉल में कुछ अतिरिक्त ओवरहेड शामिल होते हैं, इसलिए एक गैर-पुनरावर्ती फैक्टोरियल गणना थोड़ी तेज़ होगी।
निष्कर्ष: जहां आप एक सरल पुनरावृत्ति एल्गोरिथ्म के साथ एक कार्यक्रम लिख सकते हैं, बिना पुनरावर्तन के, तो आपको बिना पुनरावर्तन के लिखने की आवश्यकता है। लेकिन फिर भी, समस्याओं का एक बड़ा वर्ग है जहाँ कम्प्यूटेशनल प्रक्रिया केवल पुनरावर्तन द्वारा कार्यान्वित की जाती है।
दूसरी ओर, पुनरावर्ती एल्गोरिदम अक्सर अधिक समझने योग्य होते हैं।
|
कार्य
जनजाति की भाषा "तुम्बा-युम्बा" की वर्णमाला में; चार अक्षर: "के", "एल", "एम" और "एन". आपको n अक्षरों वाले सभी शब्द प्रदर्शित करने होंगे जो इस वर्णमाला के अक्षरों से बनाए जा सकते हैं।
समस्या एक सामान्य क्रूर-बल समस्या है जिसे एक छोटी समस्या में कम किया जा सकता है।
हम शब्द के लिए अक्षरों को क्रमिक रूप से प्रतिस्थापित करेंगे।
किसी शब्द की पहली स्थिति वर्णमाला के 4 अक्षरों (K. L, M, N) में से एक हो सकती है।
पहले K अक्षर को रखते हैं। फिर, पहले अक्षर K वाले सभी प्रकार प्राप्त करने के लिए, आपको शेष n - 1 स्थितियों में अक्षरों के सभी संभावित संयोजनों की गणना करने की आवश्यकता है। (तस्वीर देखें).
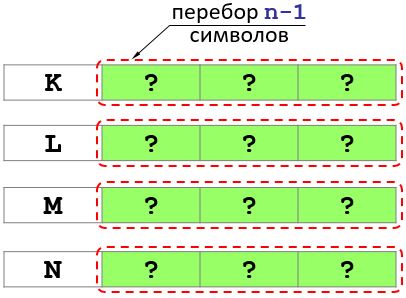 इस प्रकार, लंबाई n - 1 की चार समस्याओं को हल करने के लिए समस्या कम हो जाती है।
n वर्णों पर बार-बार पुनरावृति करें
डब्ल्यू[0]='के'; // अंतिम L-1 वर्णों पर पुनरावृति करें
डब्ल्यू[0]='एल'; // अंतिम L-1 वर्णों पर पुनरावृति करें
डब्ल्यू[0]='एम'; // अंतिम L-1 वर्णों पर पुनरावृति करें
डब्ल्यू[0]='एन'; // अंतिम L-1 वर्णों पर पुनरावृति करें
w - एक कैरेक्टर स्ट्रिंग जो वर्किंग वर्ड को स्टोर करता है।
इस प्रकार, हमें रिकर्सन मिला। हम पुनरावर्ती प्रक्रिया के रूप में समस्या के समाधान की व्यवस्था कर सकते हैं।
यह निर्धारित करना बाकी है कि पुनरावृत्ति कब समाप्त होगी? जब सभी वर्ण सेट हो जाते हैं, अर्थात सेट वर्णों की संख्या n होती है। इस मामले में, आपको परिणामी शब्द को स्क्रीन पर प्रदर्शित करने और प्रक्रिया से बाहर निकलने की आवश्यकता है।
C++ प्रोग्राम इस तरह दिखेगा।
<दिव>
#शामिल<iostream>
नेमस्पेस एसटीडी का उपयोग करना;
शून्य TumbaWords (स्ट्रिंग ए, स्ट्रिंग और डब्ल्यू, इंट एन)
// w - बदलने योग्य पैरामीटर (स्ट्रिंग-परिणाम)
// TumbaWords प्रक्रिया वर्णमाला को वर्ण स्ट्रिंग के रूप में पास करती है,
// शब्द शब्द और पहले से सेट वर्णों की संख्या (पूर्ववर्ती – 0)।
{
int मैं;
अगर (एन == डब्ल्यू आकार ())
{
// यदि सभी वर्णों को पहले ही शब्द पर सेट कर दिया गया है, तो
// फिर एक स्ट्रिंग को आउटपुट करना और प्रक्रिया को समाप्त करना आवश्यक है
cout << << एंडल;
वापस करना;
}
के लिए (i = 1; i < A.size (); i ++)
{
// यदि ऊपर दी गई स्थिति झूठी है (अर्थात, सभी वर्णों के बीच अंतर नहीं है,
// फिर लूप में हम वर्णमाला के सभी वर्णों से गुजरते हैं और
// वैकल्पिक रूप से चरित्र को पहले खाली स्थान पर रखें
डब्ल्यू [एन] = ए [i];
TumbaWords (A, w, N+1);
}
}
मुख्य()
{
इंटन;
स्ट्रिंगवर्ड;
इंटन;
सिने>> एन;
शब्द का आकार बदलें (एन); // स्ट्रिंग को आकार n तक बढ़ाएं
तुम्बावर्ड्स ("केएलएमएन", शब्द, 0);
}
w एक परिवर्तनशील पैरामीटर (परिणाम स्ट्रिंग) है!
|